Modelling Decentralization as Weighted Sets
A dense post this week

Apologies for anybody that was after a ‘light’ piece this week—instead it’s a work-in-progress piece of academic work. For a while I’ve been trying to formalize some way of structuring the agent types in a blockchain network to show how risk, cost and security are felt, and for now, I’ve settled on pursuing an angle that involves weighted sets.
In this article I’ll talk about two ways of looking at agent sets for analytical purposes: weighting the nodes in the set, and weighting the edges between nodes.
Modelling weighted edges is more informative.
The key reason is this: adding another edge always increases the total cost
from the perspective of the user, even if the weighting is small.
First however, we need to talk about how these networks are structured. Based on qualitative research, industry experience and an extensive review of the literature, we advanced a model that operates on two axes—the technical and the social.1
1. Network Topology and Governance Topology
In our work, we model a network as split across two axes:
Network topology, the physical and technical structure of the network.
Governance topology, the structure of decision making power in the network.
We summarise this in our papers as a split between the ‘protocol’ and the ‘governance of the protocol.’ It’s a useful way of looking at socio-technical systems, especially when it comes to how externalities are felt.
We hypothesise that many of the external costs generated by the network topology are assumed to be accounted for in the governance topology—however, in practice, they usually are not.
Finally, these axes—or perhaps ‘layers’ would be a better term—are stratified, in the sense that the governance of the network always takes precedence.
2. A Weighted Sets Model of Decentralization
Let’s attempt a formalisation that shows the interaction of agents as they account for the cost of security2 in a network. Following the reasoning of Budish (2025) we assume:
Adding a single node to the network always has a linear cost as the best-case
scenario; thus, the weighting factor is always at least 1.
The combined cumulative value of all nodes multiplied by their weights adds up to the combined fixed cost of security for the network.
This would not be the total cost, due to the presence of externalities3—we hypothesise that there is a negative externality associated with the cost of co-ordination in both the case of a network and a governance topology that is not accounted for on most existing ledgers.4
Excluding exogenous externalities as beyond the scope of this piece, from the perspective of a single agent submitting data to the consensus and finality process, we can model the structure of the cost of finality in terms of its locus in the subsystems and agent personas in a system.
Let’s assume, for this simplified model, that agents can be in only one subset. Thus, we might imagine the network topology of a network as a set of subsystems or nodes, S. However, different nodes or subsystems in this entity graph, for example, validators V, software implementations I, a Foundation, F, or data centres D, have different weightings for their centrality. Another way of thinking of this is in terms of their centrality to the integrity guarantees of the system in operation.
We can imagine a formalization of weighted centrality that is as follows:
A weighting function:
A function (sigma) that maps subsystems (S) to their subset or partition:
Where P is a subset, or partition of S.
This means we can use a weighting function (w) for a single subsystem (n):
To confirm the total weight sums as expected, it is possible to sum the weighted sets:
This same exercise can be completed for the governance topology of a network. As stated before, with ‘real’ values, we would expect this sum to add up to the (fixed) cost of securing a network at a given point in time.
The questions then are:
What are we weighting? There are two options:
The nodes themselves
Their relationships (which would mean we actually need to uniquely weight the edges between distinct sets, e.g. Validators (V) and Data Centres (D))
How do we represent externalities?
Asking the first question raises some questions about what exactly weighting the nodes tells us.
3. Visualising Weighted Sets as Cost Curves
The goal here is to look at all the potential places in the network that affect the integrity of our assets,5 and apply a weighting to them, which we can later express as a cost.
This shows our risk exposure as a transacting agent within a network to other agent types, as well as the relationship to the cost of security. In the next section, we will describe how this might be calculated such that it would represent a cost curve.
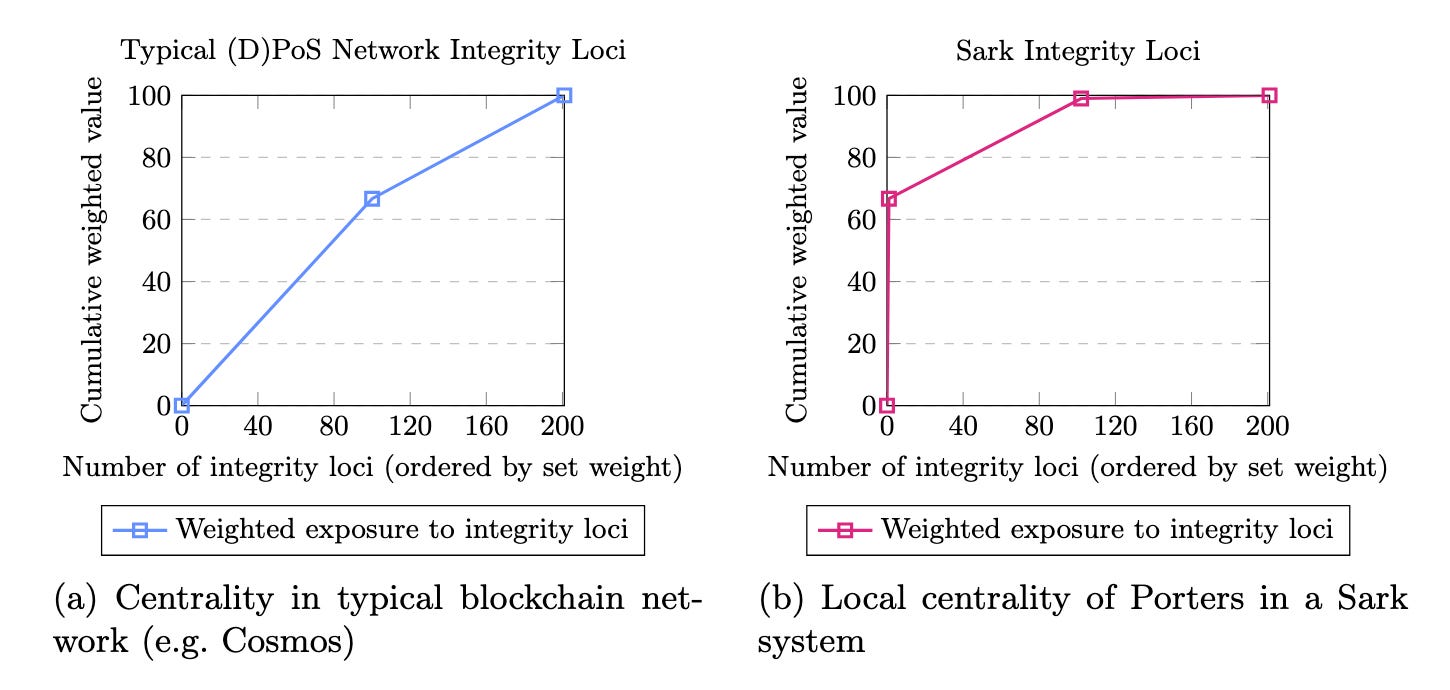
To model a public, permissionless network, we simplify the topology down to only three components: client implementations (1), validator set (100), and then all other subsystems, which we assume add up to a further 200 nodes—and to whom we apply an equal weighting.
The single client implementation is the first point of centrality, followed by the hundred validators, followed by the remaining subsystems (in this case, we allow for only one type—we could easily say it simply represents stakers).
Currently these charts use only arbitrary numbers, but if we exempt client implementation in the case of an example system such as a Cosmos blockchain or Sark network,6 we could model the effect of a ledger as single point of failure, versus a system where a higher level of trust in a single agent (a Porter) was required.7
‘Porters’ are simply the in-system name for relays, to which an asset is ‘tethered’ for its integrity. The transactable asset in Sark is the USO, an Unforgeable, Stateful, Oblivious asset8 and can only be updated by a single relay, which is identified in the asset’s data payload by the identity of the Porter which is allowed to update it.

4. Weighted Nodes vs Weighted Edges
This weighting is all very well, but it’s still not telling us much. My first intuition was the weighting could result in a gravity-weighted graph that would show the relative centrality of a Foundation or controlling entity.9
However, I think the place to take this next is to maintain the partitioned sets model, but abandon weighting the node itself, and add an additional group of sets: the edges between nodes (i.e. agent sets). By doing this, we can later use the edges to weight the node based on their relationships.
Then you can start to model value of adding an agent, and cost of adding an agent. Think of it in terms similar to Metcalfe’s Law—that adding an agent has a value, related to its set, as well as a cost.10 Of course, this is unlikely to be linear. In a BFT system, the 4th node is the most valuable systemically, and we would assume a long tail of diminishing value accrual thereafter.
For simplicity, you would weight the edges between nodes in the same sets equally (even though concerns such as voting power, jurisdiction etc might change the weighting). In practice, a Foundation might delegate a hundred USD to one validator, and a million to another, but here, we would assume equal weighting of edges (pairwise, symmetrical connections).
In an example, the subset of edges, E, should be the same whether a V (Validator) or F (Foundation) is the source. Thus, given a function that can return a weighting for an edge, given its source and target, f, the value of a node is the sum of this set of edges.
This would allow you to simply sum the value of all the edges to a given node, giving the node a concrete value.
In this simplification, it’s bi-directional, but that naive weighting might not work. At the end of this section, I’ll add some thoughts about how this relates to cost, but the intuition should be that it operates similarly to Metcalfe’s Law, and the visualisations in the previous section are simply the cost curves.
Let’s think of a visual example. Users can hold one unit of an asset—a USO in the case of Sark, and a whole token of some nominal cryptocurrency.
How would we put a number to it? For a dummy example, the intuition would be to weight the edges between two sets as 1/(number of nodes that have responsibility for integrity) in the case of integrity.
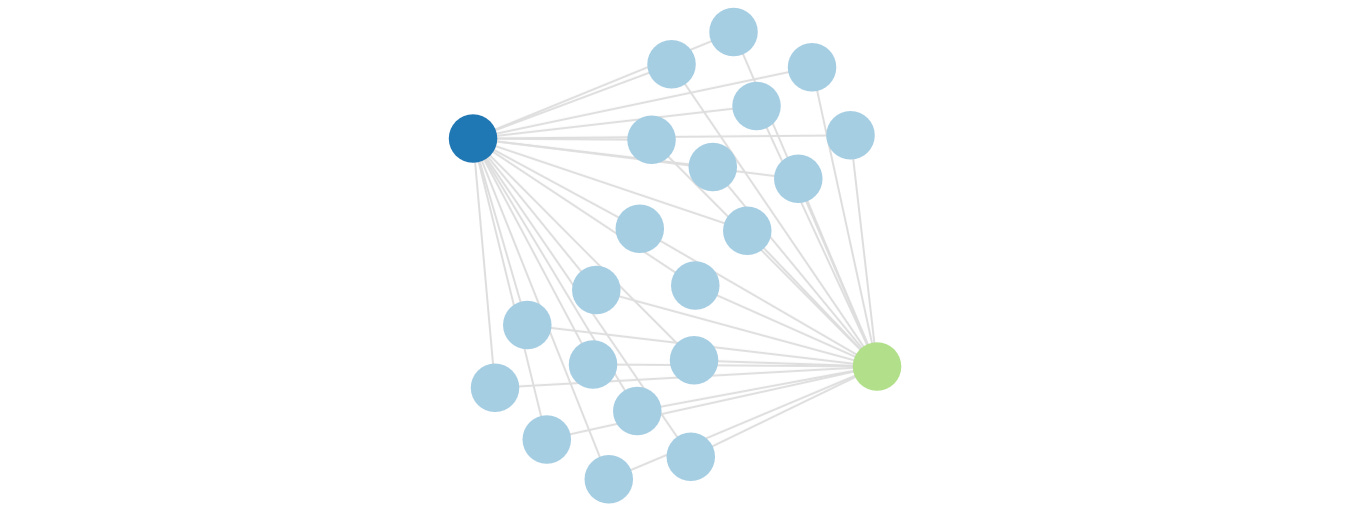
Consider the case of a Porter from the point of view of a USO asset holder—to update that asset, they (dark blue) need to talk to only the Porter (light blue) specified in the asset by either the issuer or the last holder. Therefore, the weighting of their edge with that Porter is 1 (1/1).

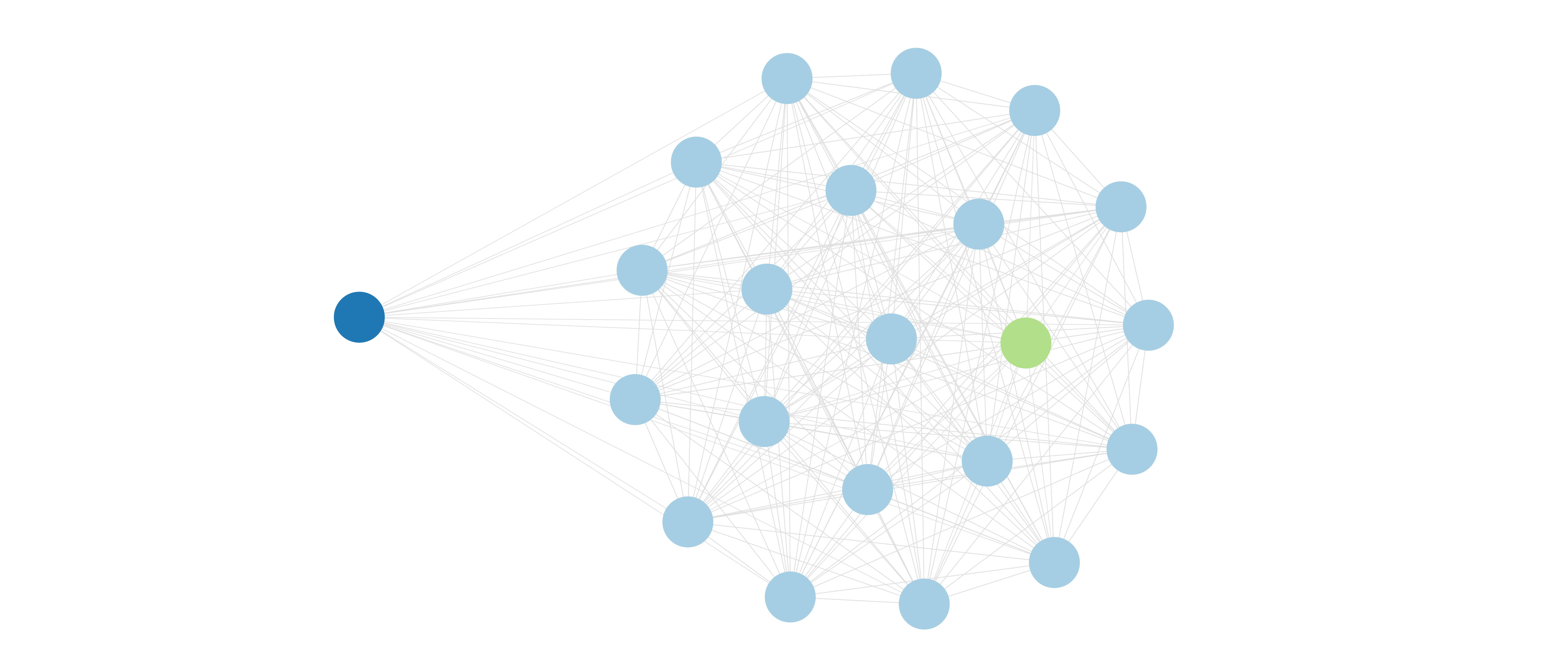
Now consider the case where we have a cryptocurrency typical of a public, permissionless network. It can be updated by sending a request to any Validator (in fact, any RPC, but let’s ignore RPCs for now in this super-simple example). We omit RPCs because we care about the subsystem responsible for integrity—the valset. RPCs are only for reads. Assuming, as in the prior examples, a valset of 100, the user’s dependence on that validator is 0.01 (1/100). The edge could be weighted by that value.
Here’s a simplified version, with 20 Validators (light blue) and a single user (blue), with a weighting of 0.05 per edge. The Validators are all assumed to be 100% reliant on the Foundation (green) for their existence/integrity (profitability). In reality, they’re somewhat dependent on users, but we base this on our fieldwork, where Validators rely on Foundations and generally don’t find gas, MEV or other incentives to be key in the long-run. However, this isn’t quite right. They’re dependent on one another too. Here they’re in a full P2P mesh.
To bring in cost, and weight the set in the context of the whole system, we need to change that value of 1 (even though in the above examples, it wouldn’t tell us much, since only validators and users are represented). Then, assuming the weighting value for each set of edges between agent sets was scaled appropriately to the total fixed cost in the network, the edges would be weighted according to cost.
In the case of adding an agent, there is a marginal cost to adding the agent, but from the perspective of a marginal transaction, this is likely to be felt as a fixed cost. The intuition here is simple: if the edges’ weighting is, in a sense, the fixed cost, these visual representations form a basic hypothesis as to whether these systems can scale, or not.
Even the existence of an edge is significant for describing the cost of system-level coordination. What it shows is that the system’s topology in terms of connections matters—in both the network topology and governance topology.
It’s easy to see that naïve decentralization (or performative decentralization, also known as ‘decentralization theatre’) along the lines of “more nodes is better” simply leads to an increase in cost. The question is—the fixed cost can be seen clearly, but if there is an external cost, then it could be exponential, depending on the node graph. How do we represent it?
Conclusion
As I suggested in the section before, it seems likely that modelling edges might be more informative. The key reason is this: adding another edge always increases the total cost, from the perspective of the user, even if the weighting is small. As you’ve probably guessed, if this logic holds, it will be coming in a paper soon.
Acknowledgements: although this work is at a very early draft stage, I think it’s valuable to try and generate some discussion, so I am putting it out there. It builds upon many discussions at UCL and specific sessions on modelling externalities and scaling permissionless networks with Prof Tomaso Aste and Dr. Geoff Goodell.
I should note that Tomaso and Geoff would likely characterise the current state of my work as not far above the ‘shower thought’ level, so no endorsement is implied or indended—merely that I value the conversations I’ve had.
These conference papers are Lynham and Goodell (2025), in proceedings of FCiR25 and SDLT 9. Pre-prints with full appendices are available here and here.
By ‘cost’ here, we mean various types of cost—sunk, fixed, and variable; the variable cost will often be talked about in the context of marginal costs here. There are also private and shared costs (external costs). As far as possible, I’ll attempt to signpost which are relevant at which point.
And, spoiler alert for the next section—variable costs.
This externality might increase with the total market cap of a network, perhaps one of the reasons that in past work we have seen both emergent self-regulation from validator sets and attempts at coercive control or control via incentives from blockchain Foundations.
And, eventually, show how obliviousness and locality affect this calculation.
Network might not be the right word exactly. The main thing with Sark is this—local relays are where assets are updated (at the edge of the system), and only double-spend protection occurs at the ledger component. In fact, once a ledger has acknowledged the asset’s inclusion on the ledger and provided a merkle root, that is included in the asset’s Proof of Inclusion, meaning—in theory—the ledger could even go away, as the Proof is now self-contained. These assets are complicated, and the subject of ongoing research.
In a traditional blockchain stack, you rely (at least marginally) on all counterparties and agents in the system. That’s the point. In Sark you rely heavily on the relay most proximal to you (your integrity anchor) and it may be that you barely (or do not) rely on other agents at all, thanks to obliviousness. The idea here is that the marginal cost should be radically sub-linear for adding new agents to the network, or perhaps even zero.
These assets are self contained; for programming language nerds, consider the difference between a monad and shared state e.g. between objects. In the monadic model, independence of data and representation is ensured by the fact the type is self-contained. This is analogous to agent independence in Sark being a function of the self-contained asset model. Obliviousness serves as both a way of ensuring privacy, but also transaction efficiency—all parties are not required to know all states. Where ‘privacy’ (after Nissenbaum) is a function of social norms and transmission context, ‘obliviousness’ is the requirement for a subsystem or agent to be oblivious.
Following the Edinburgh Decentralization Index’s MDT logic—that the underlying controlling entity is what passes or fails a minimum heuristic for decentralization. Contrast this with the Nakamoto Coefficient, which does not account for intermediated control or coercion.
Importantly for our discussion of external costs later, this was a broadcast-only model, which implies low to no cost of coordination, and/or minimal governance.